CS377: Database Design - The GEDCOM File Format (100 Points)
Assignment Goals
The goals of this assignment are:- To use file I/O to read and process records in a flat file format
- To implement a file structure standard
- To explore records, types, and relationships among data
Background Reading and References
Please refer to the following readings and examples offering templates to help get you started:The Assignment
In this assignment, you will develop a program to read a GEDCOM ancestral history file, generating object records for each individual and family relationship, and outputting a graphical family tree using the DOT graphing language.
The FamilySearch GEDCOM Specification was developed by the Family History Department of The Church of Jesus Christ of Latter-day Saints, and released under the Apache 2.0 license.
Reading the Records File
The GEDCOM file format uses a line-based hierarchical structure to represent individuals and relationships. Each line has roughly the same format, with each field separated by spaces:
NUM TYPE DATA
For example:
0 @I1@ INDI
1 NAME Kelly /Lee/
2 SURN Lee
2 GIVN Kelly
1 SEX F
1 BIRT
2 DATE 1 Jan 1990
2 PLAC Collegeville, Pennsylvania, United States of America
1 FAMC @F1@
0 @I2@ INDI
1 NAME Chris /Lee/
2 SURN Lee
2 GIVN Chris
1 SEX M
1 FAMC @F1@
0 @F1@ FAM
1 WIFE @I1@
1 CHIL @I2@
In this example, Kelly Lee has one child named Chris. On each line, the number represents the level in the hierarchy; higher numbers represent data within the umbrella of the higher number that came above. You might think of this example according to that hierarchy:
- 0 @I1@ INDI
- 1 NAME Kelly /Lee/
- 2 SURN Lee
- 2 GIVN Kelly
- 1 SEX F
- 1 BIRT
- 2 DATE 1 Jan 1990
- 2 PLAC Collegeville, Pennsylvania, United States of America
- 1 FAMC @F1@
- 1 NAME Kelly /Lee/
- 0 @I2@ INDI
- 1 NAME Chris /Lee/
- 2 SURN Lee
- 2 GIVN Chris
- 1 SEX M
- 1 FAMC @F1@
- 1 NAME Chris /Lee/
- 0 @F1@ FAM
- 1 WIFE @I1@
- 1 CHIL @I2@
The first line (0 @I1@ INDI) specifies that an individual is being defined. The 1 NAME Kelly /Lee/ line indicates that the person’s name is Kelly Lee (the slashes indicate the person’s surname, as opposed to their given name; keep in mind that this is not always the person’s “last name”). Specifically, Kelly Lee is the name of the person referred to by @I1@, because it appears below that line in the hierarchy. In general, if you read the file one-line-at-a-time, each time you encounter a 0 line, you’re defining a new person or family structure. You can read the first two tokens of each line, after tokenizing by space, to determine the hierarchy number and record type/identifier. The rest of the line is the data associated with the record, which you can de-tokenize (or append, or extract from the text of the line) and store in a variable.
Example files can be found on the GEDCOM website. The GEDCOM file format specification is large and detailed; it is not necessary to process every type of relationship. At a minimum, you should extract the names of individuals and their familial relationships (i.e., spouse, children, etc). You are welcome, and encouraged, to extract additional information as your creativity allows!
Creating the Internal Records Representation
Before you convert the records file to a graph, it is helpful to create an in-memory structure that models the individuals and relationships that you will process. Create a struct or class to represent a person, and create an object for each person that you process within your file. You should store, as fields, each piece information about the person that you intend to graph. At a minimum, this should include the person’s name, and an integer with a unique serial number that you generate (you can simply add one to this number each time you create a person object).
Create an additional struct or class to represent a relationship. This should contain a pointer to, or the serial number you created of, each person in the relationship. Create a global const int to represent each type of relationship (spouse, sibling, etc), and store the type of relationship as well. At a minimum, your structure should contain references to the two people in the relationship, and an integer representing the type of relationship. Note that you should never have more than one instance of an individual person in-memory; instead, the reference, serial number, or pointer to that object should be used in the relationship structures.
Outputting the Graph
You will use the DOT file format to generate your graph. This is another text file format in which each line represents an edge of the graph, and additional lines of text represent attributes about the node (such as label, color, and shape). Here is an example graph to help you understand the format:
digraph mygraph {
A -> B;
B -> C [label="Edge Label"];
A [label="Node A"];
B [shape=box, label="Node B", color="red"];
}
This graph generates the following image when compiled using the Graphviz parser:
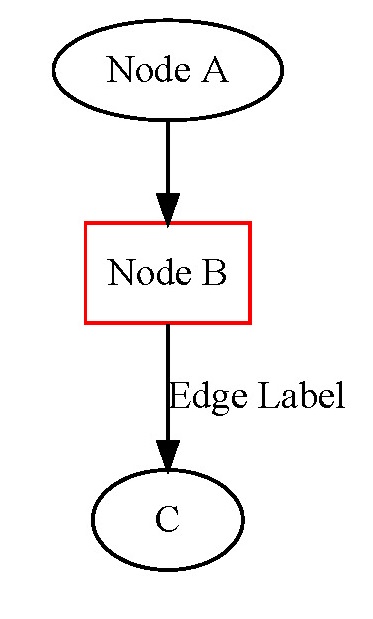
Iterate over your internal representation and output a node for each individual, and create an edge between nodes that are related (spouse, child, etc). Label each node with the name of the person, and label each edge with the type of relationship. You can label nodes and edges with additional information about the person if you’d like; feel free to get creative!
Viewing the Graph
You can convert your DOT graph to a graphical format like jpeg using the Graphviz tool. Download and install Graphviz, and you can run this command from the console:
dot -Tsvg -o example.svg example.dot
This command outputs an SVG graphic from the input dotty graph, which you can open in most web browsers. Some installations support other file formats as well; for example, you can output to a jpeg or postscript file using one of these variants:
dot -Tjpg -o example.jpg example.dot
dot -Tps -o example.ps example.dot
The -o parameter specifies the output file (here, example.jpg or example.ps), the -T parameter specifies the output file type (if you enter an invalid one, it will list the formats that the software supports), and the last parameter is the input graph filename (here, example.dot). Feel free to choose your favorite supported format, and you can open the output graph to view your results!
Testing Your Program
Create at least two family tree structures with meaningful relationships, and, using your program, generate a DOT graph for each. Convert your DOT graph to a graphical output, and verify that it correctly depicts the relationships you’ve modeled in the tests.
Exporting your Project for Submission
When you’re done, write a README for your project, and save all your files, before exporting your project to ZIP. In your README, answer any bolded questions presented on this page.
Submission
In your submission, please include answers to any questions asked on the assignment page in your README file. If you wrote code as part of this assignment, please describe your design, approach, and implementation in your README file as well. Finally, include answers to the following questions:- If collaboration with a buddy was permitted, did you work with a buddy on this assignment? If so, who? If not, do you certify that this submission represents your own original work?
- Please identify any and all portions of your submission that were not originally written by you (for example, code originally written by your buddy, or anything taken or adapted from a non-classroom resource). It is always OK to use your textbook and instructor notes; however, you are certifying that any portions not designated as coming from an outside person or source are your own original work.
- Approximately how many hours it took you to finish this assignment (I will not judge you for this at all...I am simply using it to gauge if the assignments are too easy or hard)?
- Your overall impression of the assignment. Did you love it, hate it, or were you neutral? One word answers are fine, but if you have any suggestions for the future let me know.
- Any other concerns that you have. For instance, if you have a bug that you were unable to solve but you made progress, write that here. The more you articulate the problem the more partial credit you will receive (it is fine to leave this blank).
Assignment Rubric
| Description | Pre-Emerging (< 50%) | Beginning (50%) | Progressing (85%) | Proficient (100%) |
|---|---|---|---|---|
| Algorithm Implementation (60%) | The algorithm fails on the test inputs due to major issues, or the program fails to compile and/or run | The algorithm fails on the test inputs due to one or more minor issues | The algorithm is implemented to solve the problem correctly according to given test inputs, but would fail if executed in a general case due to a minor issue or omission in the algorithm design or implementation | A reasonable algorithm is implemented to solve the problem which correctly solves the problem according to the given test inputs, and would be reasonably expected to solve the problem in the general case |
| Code Quality and Documentation (30%) | Code commenting and structure are absent, or code structure departs significantly from best practice, and/or the code departs significantly from the style guide | Code commenting and structure is limited in ways that reduce the readability of the program, and/or there are minor departures from the style guide | Code documentation is present that re-states the explicit code definitions, and/or code is written that mostly adheres to the style guide | Code is documented at non-trivial points in a manner that enhances the readability of the program, and code is written according to the style guide |
| Writeup and Submission (10%) | An incomplete submission is provided | The program is submitted, but not according to the directions in one or more ways (for example, because it is lacking a readme writeup or missing answers to written questions) | The program is submitted according to the directions with a minor omission or correction needed, including a readme writeup describing the solution and answering nearly all questions posed in the instructions | The program is submitted according to the directions, including a readme writeup describing the solution and answering all questions posed in the instructions |
Please refer to the Style Guide for code quality examples and guidelines.